
Linux - le système libre
présentation créée par Renaud Goll @ TekaTux
Document sous licence 
On va vers où ?
#!/bin/bash
echo -ne 'nom user : '
read user
echo -ne 'nom site : '
read site
if [[ -e /var/www/"$user" ]]; then
echo utilisateur existant >&2
exit 128
fi
function createBase() {
## creation de la base de donnee et du user sql
local user="$1"
local mdp="$2"
mysql -e "create database ${user//-/_};"
mysql -e "create user '${user//-/_}'@'localhost' identified by '${mdp}';"
mysql -e "grant all on ${user//-/_}.* to '${user//-/_}'@'localhost';"
mysql -e "flush privileges"
return $?
}
function createUser() {
## creation user et rep de site web
mkdir -p /var/www/"$user"/"$site"
useradd -b /var/www/"$user" -d /var/www/"$user" -M -g www-data -G sftp -N -s /bin/false "$user"
chown "$user":www-data /var/www/"$user"/"$site"
echo "$mdp" >"$user"
echo "$user:$mdp" | chpasswd
}
mdp=$(pwgen -s 16 1)
createBase "user" "mdp"
createUser "user" "mdp"
## site et vhost
sed -e "s/__USER__/${user}/g; s/__SITE__/${site}/g; s/__SITEALIAS__/${site#www.}/g" <site-generic.conf >/etc/apache2/sites-available/"$site".conf
a2ensite "$site"
systemctl reload apache2
Vers où on ne va pas ?
Vers où on ne va pas ?

Image issue de Joystick n°57, février 1995
Sommaire Jour 1
- Heroes and History
- Les Systèmes d'exploitation (OS)
- Histoire des UNIXes, de Linux et des Distributions
- Installation de Gnu/Linux
- Shell et commandes usuelles
- L'arborescence (FHS)
- Manipulation des fichiers
Sommaire Jour 2
- Substitution
- Entrée/Sortie
- Scripts
- Package Management
Sommaire Jour 3
- Gestion des utilisateurs
- Gestion FS
- Gestion Systemd
- Gestion Réseau
- logs

TekaTux
L'informatique éthique
- Hébergements écologiques
- Architecture système et réseau
- Expertise systèmes libres (unix/linux)
- Cybersécurité
- RGPD
Hall of fame
un peu d'histoire
Ada Lovelace (née byron)
|
Nationalité britannique née le 10 décembre 1815 à Londres, morte le 27 novembre 1852 Elle est connue pour être la première informaticienne. C'est la première personne a avoir écrit un programme. Celui ci pouvait être exécuté sur la machine à cartes perforées de Charles Babbage (26/12/1791 - 18/10/1871) dérivée du métier à tisser de Joseph Marie Jacquard Alors que Babbage lui même ne voit dans sa machine qu'une super calculatrice, Ada imagine et décrit déjà les principes de fonctionnement d'un calculateur universel: l'ordinateur. Elle invente notament le concept de boucle conditionnelle. |

Images wikipedia: daguerreotype by Antoine Claudet |
John Von Neumann
|
Neumann Jànos Lajos de son nom de naissance Nationalité Hongroise, puis américaine Né le 28 décembre 1903 à Budapest (Autriche-Hongrie), mort le 8 février 1957 Il est connu (en informatique) pour l'architecture de von neumann, architecture interne des ordinateurs toujours d'actualité aujourd'hui. Cette architecture centralise les différents éléments d'un ordinateur et décrit les échanges entre eux. |

Images wikipedia |
Alan Turing
|
Nationalité britannique Né le 23 juin 1912 à Maida Vale, mort le 7 juin 1954 Il est l'inventeur de la Bombe, un ordinateur mécano-électrique construit dans l'unique but de casser le code de la machine Enigma. Il remet au goût du jour les travaux d'Ada Lovelace sur les calculateurs universels. Il est aussi l'inventeur d'un certain nombre de concepts, dont celui de la machine aujourd'hui appelée machine de Turing. |

Images wikipedia |
Sir Maurice Vincent Wilkes
|
Nationalité britannique Né le 26 juin 1913 à Dudley, mort le 29 novembre 2010 Il est le créateur de l'EDSAC, premier ordinateur à architecture von neumann. Il invente aussi le concept de microprogrammation et de ROM. Plus tard, il concevra le Titan 2, premier ordinateur supportant un système d'exploitation à temps partagé. Il est aussi l'inventeur des ACL qui seront utilisées ensuite dans les Unix. |

Images wikipedia |
Louis Pouzin
|
Nationalité française Né le 20 février 1931 à Chantenay-Saint-Imbert. Il est l'inventeur du concept de transport par datagramme. Il créé le réseau Cyclade en 1972. Il fonctionnera pleinement en 1974 (25 ordinateurs en France et 2 en Europe), soit 2 ans avant Internet. Lorsque le principe des datagrammes et de la commutation par paquets est proposé aux PTT pour leur futur réseau de transfert de donnée (plus tard appelé minitel), il se heurte à un mur: les PTT avec leurs ingénieurs télécom ont choisi le X.25, protocole en mode circuit virtuel dont plus personne ne parle aujourd'hui. |

Images wikipedia |
Dennis McAllister Ritchie (dmr)
|
Nationalité américaine Né le 9 septembre 1941 à Bronxville, trouvé mort le 12 octobre 2011 Il créé le langage C, père de tous les langages modernes, comme une évolution du langage B de Ken Thompson pour écrire le premier Unix dont il est co-inventeur. Ce premier Unix a longtemps été distribué sur disquette à travers les universités. Il est donc aussi considéré comme un des pères du logiciel libre. Sa mort est éclipsée par la mort d'une star du business informatique, Steve Jobs, mort 6 semaines avant lui. |

Images wikipedia |
Brian Kernighan
|
Nationalité canadienne et américaine né le 1er janvier 1942 à Toronto Il a coécrit le livre The C programming Language avec Dennis Ritchie. Ce livre ayant eu un énorme succès est couramment appelé le Kernighan/Ritchie ou le K&R, ou encore the white book (de la couleur de sa couverture). Brian Kernighan est à l'origine du nom Unix, jeu de mot sur Unics. Il est aussi l'inventeur du langage Awk. |

Images wikipedia |
Ken Thompson
|
Nationalité américaine né le 4 février 1943 à la Nouvelle-Orléans Il est l'inventeur d'Unix qu'il écrit en B puis en C avec Dennis Ritchie et Brian Kernighan. Il est aussi l'inventeur du pipe, de ed (précurseur de vi et de tout un tas d'éditeur de texte) et de l'encodage de caractère UTF-8. |

Images wikipedia |
Vinton Gray Cerf (dit Vint Gray)
|
Nationalité américaine né le 23 juin 1943 à New Haven (Connecticut) Il est le co-inventeur, avec Robert Elliot Khan, du protocole TCP/IP et utilise pour ce faire les travaux du projet Cyclade de Louis Pouzin. Il est le fondateur de l'ISOC (Internet Society) qui soutien notamment l'IETF (Internet Engineering Task Force). |

Images wikipedia |
Richard Mathieu Stallman (rms)
|
Nationalité américaine né le 16 mars 1953 à New York Il est l'inventeur du concept de logiciel libre, fondateur de la Free Software Foundation (FSF) et grand pourfendeur du logiciel propriétaire. Pour lui, un code (informatique) ne peut pas plus appartenir à quelqu'un qu'une opération mathématique. Il est le créateur et programmeur principale du jeu de commande GNU que nous utilisons tous par défaut sous linux. C'est encore aujourd'hui le mainteneur principal de l'éditeur emacs. |

Images wikipedia |
Sir Thimothy John Berners-Lee (dit Tim Berners-Lee)
|
Nationalité britannique né le 8 juin 1955 à Londres Il est l'inventeur du World Wide Web (www). D'après ses propres paroles (je cite): Je n'ai fait que prendre le principe d’hypertexte et le relier au principe du TCP et du DNS et alors – boum ! – ce fut le World Wide Web !. C'est simple, non ? Il a travaillé pour le CERN en France dans les années 1980 où il fut connecté au réseau ARPANET. C'est à priori de là que viens son idée de www. Il a fondé et préside le w3c. |

Images wikipedia |
Linus Torvalds
|
Nationalité finlandaise et américaine né le 28 décembre 1969 à Helsinki Il est le développeur principal et l'initiateur du projet linux. Ce noyau de système d'exploitation équipe aujourd'hui plus de 50% des appareils informatiques dans le monde. Linux est sous licence libre pour des raisons pratiques. En effet, le choix d'une licence libre pour Linus ne trouve pas de racines politiques, d'où de nombreuses batailles avec Richard Stallman entre autre. Longtemps géré à la main, le versioning de linux se fait avec BitKeeper (qui est propriétaire) jusqu'à ce que la version gratuite disparaisse. Linus écrit alors Git qui est aujourd'hui une référence en la matière. |

Images wikipedia |
Et les autres ?
Beaucoup de monde a été oublié dans cette présentation. Je ne parle pas par exemple des acteurs de Palo Alto, des inventeurs de ethernet, ou de Douglas Engelbart (inventeur de l'informatique moderne), etc.
Il y en a deux que je n'ai pas oublié en revanche, c'est Steve Jobs et Bill Gates. Ceux là sont des industriels qui n'ont jamais rien inventé d'autre que le fait de vendre beaucoup à beaucoup de monde. Cela dit, c'est grace à eux que l'ordinateur s'est démocratisé.

Histoire des OS
Ici, une "pascaline", calculatrice mécanique de 1642
1949: l'EDSAC

|
|
1956: Le GM-NAA io pour IBM 704

console de l'opérateur |
|
1968: the mother of all demos sur NLS
Regardez sur invidious: The Mother of All Demos, presented by Douglas Engelbart (1968) [HD 720p 2020 reupload]

|
|
1970: UNIX et le PDP-11 de Nec

PDP11 avec DECtapes |
|
1973: Xerox Alto OS

Notez l'écran "portrait" |
|
1976: OpenVMS et le VAX-11

l'unité centrale |
|
Ce qu'il faut retenir
- Le premier, c'est 1949
- 1956: système mono tâche, mono utilisateur
- 1970: système multitâche, mono utilisateur (et UNIX)
- 1973: système multitâche, multi utilisateur
- 1976: système temps réel
- Linux nait en 1991 (v0.1), 1994 pour la v1.0
- Windows implémente le Multi tâche en 2003...
Les systèmes d'exploitation
Définition
|

|
C'est la couche d'abstraction matérielle
Quelques système d'exploitation
|
|

|

|
Architecture des OS modernes

Histoire de Linux
et de ses distributions
Histoire d'unix

Histoire de Linux

philosophie
less-is-more philosophy
|
|
|
|
|
|
|
|
Conséquences
- Sous UNIX, tout est fichier
Fichiers, répertoires, devices, RAM...
- Sous UNIX les fichiers doivent être
- lisibles par l'homme
- exploitables simplement par la machine

- Ce qui en découle
- Pas de fichiers binaires (comme le registre)
- Pas de format propriétaire (docx...)
- Structure simple: pas de xml
- Principe KISS
Linux aujourd'hui
- OS stable
- Fonctionne sur plusieurs achitectures dont
- Intel X86 (les PCs, quoi)
- ARM (tablettes, smartphones...)
- SPARC
- m68k (Macintosh collector)
- Power PC(Macintosh aussi)
- MIPS
- RISC-V
- ...
- usage courant en informatique embarquée
- Téléphonie
- Cloud
Quelques distributions


Linux Install
Windows et la virtualisation
- Hyper-V
- gratuit... mais jusqu'à quand ?
- uniquement dans les versions pro et education
- migration de machine ?
- Windows Subsystem for Linux
- haute performance
- sécurité ?
- mise à jour de version majeure ?
- VirtualBox
- Sous licence GPL v2
- migrable, portable
- performance ?
- accès au hardware
Installation sous VirtualBox (Oracle)
TD Installation VirtualBox
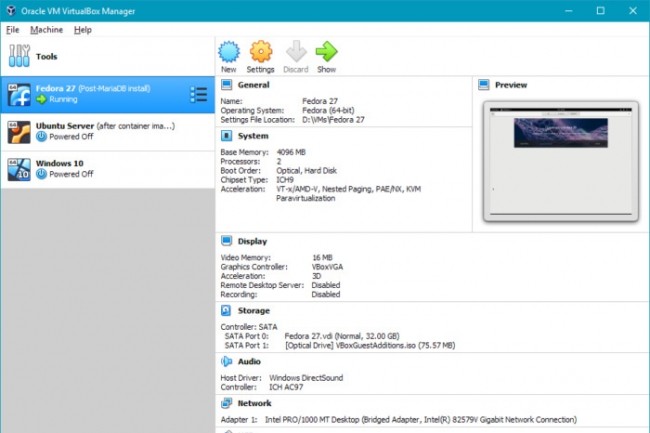
- Télécharger VirtualBox
- Installer
- Lancer
TD Installation debian
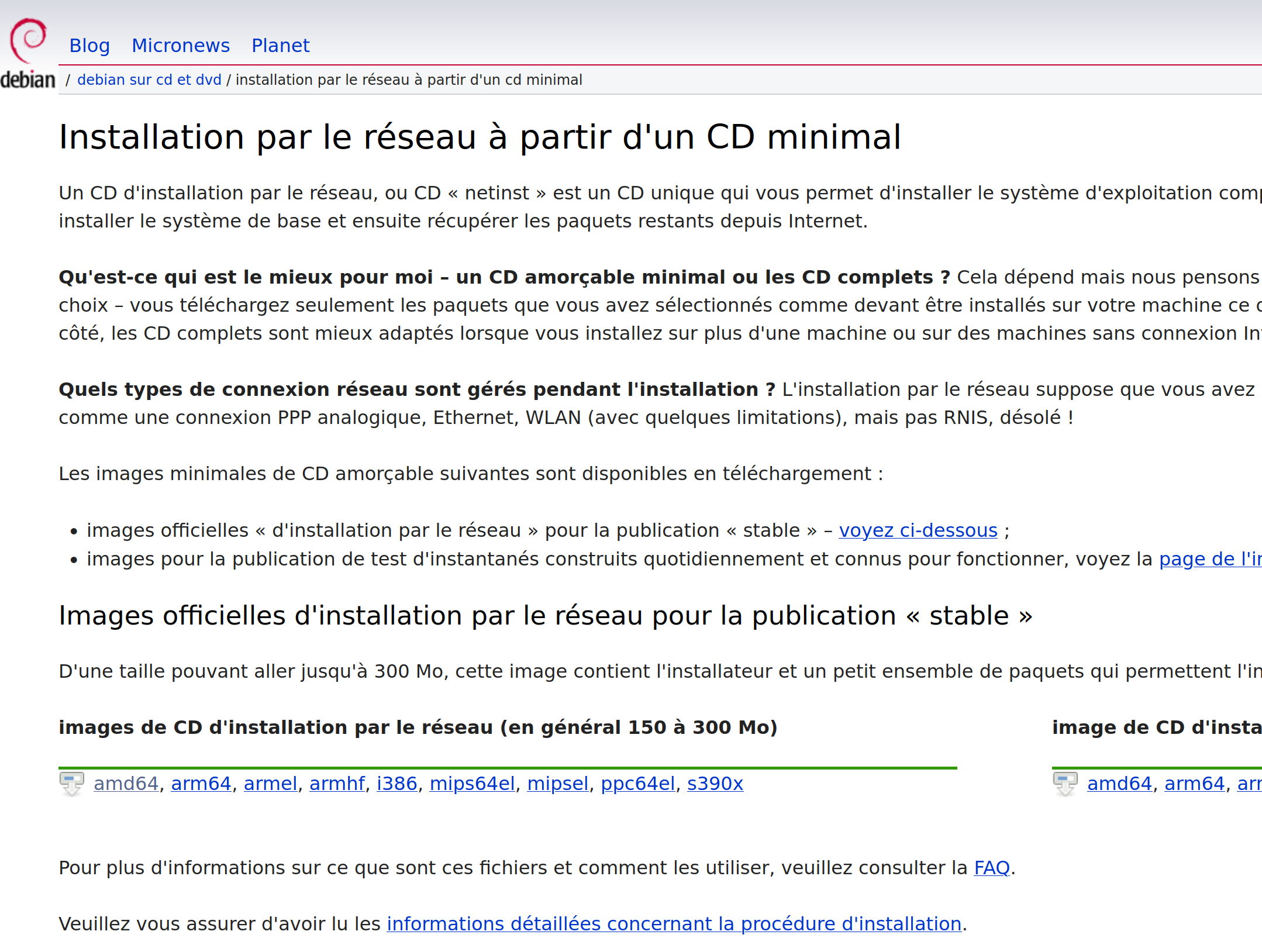
Télécharger CD "netinst" pour architecture AMD64
https://www.debian.org/CD/netinst/
et cliquez sur amd64
Les points saillants
VirtualBox
- Cliquer sur Nouvelle (pas sur +)
- RAM: 1024Mo
- Créer un disque dur format VMDK Dynamique
- Disque de taille 8Go
- Cliquez sur menu Configuration
- Ajouter CD netinst
- Démarrer la VM
Les points saillants
Installation Debian
- Choisir installation texte
- Système en français
- Partitionnement disque entier avec LVM et /home séparé
- Miroir de l'archive ftp.fr.debian.org (par exemple)
- Pas d'installation de GNOME... mais seulement SSH et Utilitaires usuels
- Grub installé sur /dev/vda ou (/dev/sda)
Loguez vous
Et welcome home
shell
La "coquille"
- fournit une interface
- Il en existe plein
(sh, bash, ksh, zsh, csh, et dans une moindre mesure, powershell) - permet la gestion complète de la machine
Le Bash
un langage faiblement structuré, non typé, standard
- Affiche un "prompt"
- exécute des commandes
- Les commandes sont généralement des exécutables (des programmes)
- Elles fonctionnent comme des filtres ou des interfaces (mais pas les deux à la fois)
Le prompt
C'est le signal d'attente du shell
- peut être de plusieurs formes paramétrables
nom@machine:~$- où nom est le nom d'utilisateur
- machine est le nom de la machine
- : est un séparateur
- ~ est le nom de répertoire courant
- termine par $ ou > si l'utilisateur est un utilisateur standard
- termine par # si l'utilisateur est le super utilisateur (le root)
La commande
- Une commande est une suite facultative d'affectations, suivie de 1 ou plusieurs mots séparés par des blancs et des redirections, et terminé par un opérateur de contrôle
- Le premier mot spécifie la commande à exécuter
- Les mots restants sont transmis comme argument à la commande appelée
Quelques exemples
$ ls
$
ls : listing : liste le contenu d'un dossier (répertoire)
$ mkdir toto
$ ls
toto
$
mkdir : make directory : créer le répertoire (dossier) toto
Quelques exemples
$ rmdir toto
$ ls
$
rmdir : remove directory : supprime un répertoire s'il est vide
~ $ mkdir toto
~ $ ls
toto
~ $ cd toto
~/toto $ cd .. ## .. = répertoire père
~ $
cd : change active directory : change le répertoire courant
Attention, cd est une commande interne
Quelques exemples
Vous êtes maintenant capable de vous déplacer dans une arborescence
ls # liste le contenu d'un répertoire
cd # change le répertoire courant
mkdir # créer un répertoire
rmdir # supprime un répertoire
il ne reste que la commande man pour être complet
man command # affiche le manuel de la commande command
exemple :
man ls # affiche le man de 'ls' (touche q pour quitter)
L'arborescence
la hierarchisation de l'information
- un chemin simple est de la forme "nom" où nom est un nom de fichier
- un chemin est un parcours dans l'arborescence
- il est composé des noms des fichiers parcourus séparé par le caractère "/"
- le chemin est dit relatif s'il commence par un nom, par "." ou par ".."
- le chemin est dit absolu s'il commence par la racine (notée "/")
- le chemin "." est le répertoire courant
- le chemin ".." est le chemin père
- le chemin est sensible à la casse (majuscules/minuscules)
# exemples
/ # chemin absolu : root (ou racine du système de fichier)
./Docs # chemin relatif : répertoire Docs dans le répertoire courant
../var # chemin relatif : répertoire var dans le répertoire père
./Docs/var # chemin relatis : rep var dans le rep Docs, dans le rep courant
Faites marcher votre tête
la copie est autorisée (et le test aussi)
- Que fait la commande
mkdir -p ./Docs/cours1elle créer un dossier "cours1" dans le dossier "Docs" situé dans le répertoire courant. Si Docs n'existe pas, elle le créer aussi (option -p)
méthode :
$ man mkdir $ mkdir -p ./Docs/cours1 $ ls Docs $ ls ./Docs # ou moins bien mais marche aussi : ls Docs cours1 $
Faites marcher votre tête
- Que fait la commande
rmdir Docs$ man rmdir $ ls Docs $ rmdir Docs rmdir: impossible de supprimer 'Docs': Le dossier n est pas vide $ ls Docs $Elle "plante": elle dit que le dossier n'est pas vide
En réalité, elle ne plante pas du tout... On lui demande de faire quelque chose qu'elle ne doit pas faire, ce qui n'est pas tout à fait la même chose... rmdir ne supprime les répertoires que si ceux-ci sont vides : c'est une mesure de précaution pour ne pas perdre une arborescence complète. Pour supprimer Docs, il faut le "vider" d'abord.
$ rmdir ./Docs/cours1 # supprime cours1 dans Docs $ rmdir ./Docs # supprime Docs désormais vide # une remarque ? $ ls $
Faites marcher votre tête
- Que fait la commande
mkdir -p ./cours/cours1/../cours2La commande crée les répertoires cours1 et cours2 dans le répertoire cours
Il suffit de suivre le guide: on part de ".", on crée cours, on crée cours1 dans cours, on remonte dans cours, on crée cours2.
$ ls $ mkdir -p ./cours/cours1/../cours2 $ ls cours $ ls cours cours1 cours2 $C'est la méthode crade... On écrira plutôt
mkdir -p ./cours/cours1 ./cours/cours2 ## ou mieux: mkdir -p ./cours/cours{1,2}
L'arborescence standard (FHS)
Filesystem Hierarchy Standard
- La racine ou le root "/"
- bin (obsolete): binaires essentiels
- sbin (obsolete): binaires essentiels pour root
- boot : kernel/init RAMfs
- dev : périphériques
- etc : fichier de configuration
- home : home des utilisateurs
- lib : bibliothèques et modules du kernel
- media, mnt : montage des filesystems temporaires
- proc : fichier d'information kernel et process
- root : home du root
- usr : applications et données d'application en lecture seule
- var : fichiers de données variables
pour les curieux...
$ ls /
...
$ ls /etc
...
L'arborescence standard (FHS)
Filesystem Hierarchy Standard
- /usr
- bin : binaires essentiels
- include : fichier include standard pour langage C
- lib : bibliothèque
- local : usr local
- sbin : binaire essentiel pour root
- share : fichiers de donnée partagé entre architectures
$ ls /usr/bin
...
$ ls /usr/share
...
L'arborescence standard (FHS)
Filesystem Hierarchy Standard
- /var
- cache : cache applicatif
- lib : données modifiables en cours d'exécution
- lock : fichiers de verrouillage des processus
- log : fichiers de logs
- mail : ... à votre avis ?
- spool : spool applicatif (spool/mail, spool/rsyslog, ...)
$ ls /var/log
...
L'arborescence standard (FHS)
Filesystem Hierarchy Standard

Les fichiers standards
pour une fois, vous les appelez comme moi !
- ce sont les conteneurs de données
- ils appartiennent à au moins 1 fichier répertoire (on dit qu'ils ont un lien dans le répertoire)
- ils possèdent des méta données (comme tous les fichiers)
- on peut les "créer" avec la commande
touch - on peut les supprimer avec la commande
rm(en réalité, on supprime un lien) ou avec la commandeunlink
Quelques exemples
la commande touch
$ ls
$ touch fichier
$ ls
fichier
$ ls -l fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 22:46 fichier
$
En réalité, le rôle de touch est de changer l'heure de modification des fichiers par l'heure courante, mais si le fichier n'existe pas, alors il est créé.
$ man touch
Quelques exemples
détail de la sortie longue de ls

Manipulations de fichiers
la commande ln
Préparation:
$ mkdir source cible
$ touch ./source/fichier
$ ls -l ./source/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 22:46 fichier
$
Exécution:
$ ln source/fichier cible/
$ ls -l source/fichier
-rw-rw-r-- 2 rg rg 0 sept. 22 23:09 source/fichier
$ ls -l cible/fichier
-rw-rw-r-- 2 rg rg 0 sept. 22 23:09 cible/fichier
$
la commande ln lie la cible à un autre répertoire (le lien est passé à 2). Le fichier "fichier" n'est présent qu'une fois sur le disque mais est accessible dans 2 répertoires
Manipulations de fichiers
la commande rm
$ ls cible
fichier
$ rm cible/fichier
$ ls cible
$
La commande rm supprime le lien du fichier dans le répertoire (courant par défaut, nommé sinon)
Manipulations de fichiers
la commande cp
Préparation:
$ ls -l ./source/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 22:46 fichier
$
Exécution:
$ cp source/fichier cible/
$ ls -l source/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 23:09 source/fichier
$ ls -l cible/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 23:09 cible/fichier
$
La commande cp copie un fichier source dans une cible. C'est une commande complexe avec de nombreuses options
Manipulations de fichiers
la commande mv
Préparation:
$ rm ./cible/fichier
$ ls -l ./source/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 22:46 fichier
$
Exécution:
$ mv source/fichier cible/
$ ls -l source/
$ ls -l cible/fichier
-rw-rw-r-- 1 rg rg 0 sept. 22 23:09 cible/fichier
$
La commande mv déplace les fichiers. Son comportement est différent en fonction du type de fichier de ses arguments
Manipulations de fichiers
la commande stat
$ stat source/fichier
Fichier : source/fichier
Taille : 0 Blocs : 16 Blocs d'E/S : 4096 fichier vide
Périphérique : 38h/56d Inœud : 1059414 Liens : 2
Accès : (0664/-rw-rw-r--) UID : ( 1000/ rg) GID : ( 1000/ rg)
Accès : 2022-09-22 23:09:25.068295540 +0200
Modif. : 2022-09-22 23:09:25.068295540 +0200
Changt : 2022-09-22 23:10:24.452466827 +0200
Créé : -
$
La commande stat affiche les métadonnée des fichiers en argument. Elle admet un paramètre -f...
Manipulations de fichiers
la commande file
$ file source/fichier
empty
$ file source
source: directory
$ file /bin/bash
/bin/bash: ELF 64-bit LSB shared object, x86-64 ...
$
La commande file affiche le type des fichiers en paramètre
la commande type
$ type bash
bash est /usr/bin/bash
$ type cd
cd est une primitive du shell
$ type ls
ls est un alias
$
La commande type affiche le type des commandes en paramètre
Manipulations de fichiers
On vient de voir
## manipulation des répertoires
mkdir ## crée un répertoire
rmdir ## supprime un répertoire vide
cd ## change le répertoire courant
## manipulation des fichiers
touch fichier ## Met à jour l'heure de modification du fichier ou le créer
rm fichier ## supprime le lien du fichier dans le répertoire
ln source rep ## rajoute un lien (dit hard) du fichier source vers rep
cp source cible ## copie le fichier standard source sur (ou dans) cible
mv source cible ## déplace source vers cible
## interfaces de lecture
stat fichier ## écrit les métadonnées de fichier
file fichier ## affiche le type de fichier
type fichier ## affiche le type de commande
ls fichier ## liste l'argument
L'ensemble de ces commandes permettent de faire grossièrement à peu près tout sur un système de fichier. Il ne manque que la synchronisation qu'on verra plus tard (en traitant le problème des backups).
Les autres types de fichiers
autre que répertoire et fichier standard
- Les périphériques. Ce sont des fichiers de type bloc ou texte. On les trouves essentiellement dans
/dev
$ ls -l /dev/vda
brw-rw---- 1 root disk 254, 0 23 sept. 18:54 /dev/vda
$ ls -l /dev/tty
crw-rw-rw- 1 root tty 5, 0 23 sept. 18:54 /dev/tty
$
$ ls -l /var/run/udev/control
srw------- 1 root root 0 23 sept. 18:54 /var/run/udev/control
$
à vous
Votre patron vous demande de créer le répertoire de travail d'un collègue. Ce collègue travaille sur 2 projets: le projet "sync" et le projet "fstrim". Vous devez lui créer une arborescence: des répertoires au nom de chaque projet contenant chacun un répertoire "c" et un répertoire "h". Les répertoires "c" devront contenir un fichier "[nom du projet].c" et les répertoire "h"[nom du projet].h. Dans chaque répertoire du projet, devra se trouver un fichier "makefile".

des solutions...
$ mkdir -p sync/c sync/h fstrim/c fstrim/h
$ touch sync/makefile sync/c/sync.c sync/h/sync.h
$ touch fstrim/makefile fstrim/c/fstrim.c fstrim/h/fstrim.h
$
à vous
Votre collègue vous engueule: le projet "fstrim" est écrit en assembleur, pas en c. Il faut donc supprimer les répertoires "c" et "h" ainsi que leur contenu et les remplacer par un répertoire "asm" avec un fichier "fstrim.asm" dans le celui ci.
des solutions...
$ rm fstrim/c/fstrim.c fstrim/h/fstrim.h
$ rmdir fstrim/c fstrim/h
$ mkdir fstrim/asm
$ touch fstrim/asm/fstrim.asm
$
ou encore
$ rm -r fstrim/c fstrim/h
$ mkdir fstrim/asm
$ touch fstrim/asm/fstrim.asm
$
Substitution
- Le BASH est avant tout un programme de substitution
- il repère des caractères spéciaux et substitue ces caractères par leur correspondance
- Les substitution sont gérés par les caractères " et '
- Entre ", seuls la substitution de variable a lieu
- Entre ', aucune substitution n'a lieu
- Pour retirer temporairement la signification d'un caractère spécial, on le fait précéder de \
Substitution
Pour chaque ligne de commande, Bash effectue 7 opérations appelées "remplacement", "développement" ou "substitution". Ces opérations sont
- Le développement des accolades: (
mkdir -p cours/cours{1,2}?) - Le développement du tilde (~)
- Le remplacement des paramètres (les variables)
- La substitution de commande (commande exécutée dans une commande)
- Le développement arithmétique (calculs)
- La substitution de processus (super | )
- Le développement des chemins (globbing: man 7 glob)
Ces développement sont effectués dans cet ordre
Substitution
Le développement des accolades
Le développement des accolades a lieu entre accolades non précédées par le signe $
- les chaines séparées par des virgules sont développées en chacune des chaines en gardant préfixes et suffixes:
{1,f5,coucou}est développé en1 f5 coucou
ab{cd,ef,gh}ijest développé enabcdij abefij abghij - les objets séparés par ".." sont développés en ensemble logique avec incrément de 1
{1..5}est développé en1 2 3 4 5
{f..j}est développé enf g h i j
{f..a}est développé enf e d c b a
Les ensembles incohérents ne sont pas développés - Dans cette deuxième forme, on peut fixer l'incrément
{1..10..3}est développé en1 4 7 10
Substitution
Le développement des accolades
Comment on s'en sert ?
$ mkdir -p cours/cours{1,2}
## est développé en : mkdir -p cours/cours1 cours/cours2
$ touch fichier{1..3}.{c,h}
## est développé en : touch fichier1.{c,h} fichier2.{c,h} fichier3.{c,h}
## lui même développé en : touch fichier1.c fichier1.h fichier2.c fichier2.h fichier3.c fichier3.h
Substitution
Le développement du Tilde ~
- Le tilde ~ est développé en le chemin du propriétaire du process.
- Le nom utilisé est le nom réel (RUID), pas le nom effectif (EUID)
$ echo ~
/home/rg
$ exit
....
login: root
password:
...
# echo ~
/root
#
Substitution
Le remplacement des paramètres (variables)
- Un paramètre contient une valeur
- Une variable est un paramètre nommé
- Le nom est composé de lettres et de chiffres
- Une variable est soumise au développement du tilde, au remplacement des variables, à la substitution de commande, à l'évaluation arithmétique et à la suppression des protections
- On affecte une valeur à une variable avec le métacaractère =, il ne doit pas y avoir d'espace entre le nom de la variable et le métacaractère =
- Une variable existe à partir du moment ou on lui affecte une valeur, y compris la valeur NULL
- Une variable est détruite avec la commande interne
unset - Une substitution de paramètre est effectuée en utilisant la forme
$NomVarou${NomVar}
Substitution
Le remplacement des paramètres (variables): exemples
Exemples simples sans protection
$ var=coucou
$ echo $var
coucou
$ echo ${var}
coucou
$ echo $var2
$ echo ${var}2
coucou2
$
Exemples plus riche, avec différents types de protections
$ var=mon fichier
fichier: commande introuvable
$ echo $var
mon
$ var="mon fichier"
$ echo $var
mon fichier
$ autre_var=$var
$ echo $autre_var
mon fichier
$ autre_var='$var'
$ echo $autre_var
$var
$ autre_var="J'ai mis $var dans "\''$var'\'
$ echo $autre_var
J'ai mis mon fichier dans '$var'
$
Substitution
Le développement des chemins
On utilise des caractères particuliers qui servent à décrire des pattern
- *: représente 0 ou plus caractère quelconque. Si aucune correspondance n'est trouvé, il n'est pas substitué
- ?: représente 1 caractère quelconque. Si aucune correspondance n'est trouvé, il n'est pas substitué
- [...]: une plage de caractère. [a-z] représente tous les caractères minuscule, [0-9] tous les chiffres, [123] les caractères 1, 2 et 3 (peut aussi s'écrire [1-3])
Ne confondez pas le développement des chemins (qui est un développement sur des noms de fichiers existant) et celle des accolades (qui est simplement un développement texte)
Substitution
Exemples
$ touch fichier{1,2}.{c,d}
$ ls
fichier1.c fichier1.d fichier2.c fichier2.d
$ rm fichier?.c
$ ls
fichier1.d fichier2.d
$ rm fichier1?.d
impossible de supprimer 'fichier1?.d'...
$
Substitution
La substitution de commande
- Il s'agit d'exécuter une commande dans une autre
- On utilise la notation '`' (backquote ou AltGr è) ou $(liste)
$ ls -a
. .. .bash_history .bash_logout .bashrc
$ mavar=`ls -a` #ou mavar=$(ls -a)
$ echo $mavar
. .. .bash_history .bash_logout .bashrc
$
À vous
Mais commencez par créer un répertoire de test et par le choisir comme répertoire courant...
$ mkdir test
$ cd test
$
Creez 26 dossiers portant comme nom les lettres de l'alphabet et dans chacun d'eux, 100 dossiers numérotés de 1 à 100.
$ mkdir -p {a..z}/{1..100}
$
Et détruisez les (sans erreurs, évidemment)
$ rm -rf *
## ou, beaucoup plus propre car ne concernant que les répertoires
$ rmdir {a..z}{/{1..100},}
Environnement d'exécution
la clé de voûte
- permet le partage des ressources
- permet la protection de chaque ressources
- permet la transmission de l'environnement
- permet la différentiation des différents environnements
Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

Environnement d'exécution
la clé de voûte

les entrées/sorties (I/O)
On connaît des programmes qui lisent des données (le bash, par exemple)
On connaît des programmes qui affichent des choses (ls par exemple)
Puisque "tout est fichier", c'est quoi les fichiers en question ?
les entrées/sorties (I/O)
- Le fichier d'entrée standard est le fichier 0 (stdin)
- Le fichier de sortie standard est le fichier 1 (stdout)
- Le fichier d'erreur standard est le fichier 2 (stderr)
- l'existence de ces fichiers est garantie par le noyau
Par défaut, le fichier d'entrée standard est relié au clavier, les fichiers de sorties et d'erreur sont liés au TTY (l'écran...)
L'ensemble de ces fichiers est appelé standard i/o ou std i/o. Leur définition est contenu (en C) dans la bibliothèque stdio.h qui sera quasi systématiquement inclus dans les programmes grace à:
#include <stdio.h>
La sortie standard
et ne dites pas "l'écran"
$ echo Bonjour monde
Bonjour monde
$ echo Bonjour monde
Bonjour monde
$
La commande echo fait un echo sur la sortie standard de ses paramètres
Cette sortie peut être redirigé ailleurs, vers un fichier standard par exemple, avec l'opérateur ">"
$ ls
$ echo Bonjour monde >monfichier
$ ls -l monfichier
-rw-rw-r-- 1 rg rg 14 sept. 23 16:36 monfichier
$
La sortie standard
et ne dites pas "l'écran"
- le méta-caractère ">" créer un fichier en écriture
- le méta-caractère ">>" ouvre un fichier en ajout
- le méta-caractère "<" redirige un fichier vers l'entrée standard
on peut rediriger n'importe quel flux, y compris les i/o standard (/dev/null est un trou sans fond: c'est la poubelle d'unix)
## redirige stderr (fichier 2) vers /dev/null
$ echo coucou 2>/dev/null
coucou
## redirige stderr vers /dev/null et stdout sur stderr (donc aussi)
$ echo coucou 2>/dev/null 1>&2
$
La sortie standard
et ne dites pas "l'écran"
- La commande
catconcatène les fichiers en arguments ou sur son entrée standard avec le paramètre - et les écrits sur sa sortie standard
$ echo coucou >fichier1
$ echo toto >fichier2
$ cat fichier1 fichier2
coucou
toto
$ cat - fichier1 <fichier2
toto
coucou
$
à vous de jouer
Que fait la suite de commande
$ echo bonjour >f1
$ echo chez >f2
$ echo vous >f3
$ cat f1 f2 f3
cat écrit sur sa sortie standard, c'est à dire affiche à l'écran, le contenu concaténé de f1, f2 et f3
$ cat f1 f2 f3
bonjour
chez
vous
$
et, avec une redirection de plus :
$ cat f1 f2 f3 >f4
La même chose en écrivant le résultat dans le fichier standard "f4". Le fichier est vidé au préalable.
à vous de jouer
Avec les mêmes fichiers, que fait la commande
$ cat - f2 <f1 >>f4
Elle concatène les fichiers standard f1 et f2, et écrit le résultat à la fin du fichier standard f4 (en mode ajout)
le génie d'unix: le pipe
ou comment écrire d'un programme dans un autre
- le "pipe" permet de rediriger la sortie standard d'un programme dans l'entrée standard d'un autre
- le code de sortie d'un pipe est le code de sortie de la dernière commande
Pour quelques commandes de plus
cut: enlève des sections de ligne d'un fichiersort: trie les lignes d'un fichiersed: éditeur de flux en ligne de commandegrep: recherche de motif dans des fichiersuniq: affiche les lignes d'un fichier en supprimant les occurrences consécutives
Pour quelques exemples de plus
Une petite préparation est nécessaire...
$ echo Bonjour monde 10 >fichier
$ echo 1 >>fichier
$ echo 2 >>fichier
$ echo 1 >>fichier
$ echo Au revoir >>fichier
$
Pour quelques exemples de plus
écrit le premier champ du fichier, chaque champ étant séparé par un espace
$ cut -d ' ' -f 1 fichier
Bonjour
1
2
1
Au
$
écrit le premier champ du fichier, chaque champ étant séparé par un e
$ cut -d 'e' -f 1 fichier
Bonjour mond
1
2
1
Au r
$
Pour quelques exemples de plus
trie le fichier dans l'ordre alphabétique
$ sort fichier
1
1
2
Au revoir
Bonjour monde 10
$
N'affiche que les chiffres
$ grep -o '[0-9]*' fichier
10
1
2
1
$
Affiche les lignes ne contenant que des chiffres
$ sed -ne '/^[0-9]*$/p' fichier
1
2
1
$
Pour quelques commandes de plus
On vient de voir
## manipulation des répertoires
mkdir ## crée un répertoire
rmdir ## supprime un répertoire vide
cd ## change le répertoire courant
## manipulation des fichiers
touch fichier ## Met à jour l'heure de modification du fichier ou le créer
rm fichier ## supprime le lien du fichier dans le répertoire
ln source rep ## rajoute un lien (dit hard) du fichier source vers rep
cp source cible ## copie le fichier standard source sur (ou dans) cible
mv source cible ## déplace source vers cible
## interfaces de lecture
stat fichier ## écrit les métadonnées de fichier
file fichier ## affiche le type de fichier
type fichier ## affiche le type de commande
ls fichier ## liste l'argument
## les filtres
cut fichier ## enlève des sections de ligne d'un fichier
sort fichier ## trie les lignes d'un fichier
sed [reg] fichier ## éditeur de flux en ligne de commande
grep [reg] fichier ## recherche de motif dans des fichiers
uniq fichier ## affiche les lignes d'un fichier en supprimant les occurrences consécutives
A vous
N'afficher que les lignes ne contenant que des lettres et le caractère espace
$ sed -ne '/^[a-zA-Z ]*$/p' fichier
Au revoir
$
Par extension, n'afficher que le premier mot des lignes sélectionnées
$ sed -ne '/^[a-zA-Z ]*$/p' fichier | cut -d ' ' -f 1
Au
$
afficher les différents chiffres de fichier, ordonnés numériquement. Chaque chiffre ne doit apparaître qu'une fois, la sortie ne doit pas contenir les lignes ne contenant pas de chiffre
$ grep -o '[0-9]*' fichier | sort -n | uniq
1
2
10
$
Les scripts
- Ce sont des ensembles de commandes regroupées au sein d'un fichier
- Les scripts permettent l'accès aux arguments à travers les paramètres positionnels
- Le langage Bash possède des structures de contrôle (if, then, while, for, case...)
- N'oubliez pas la philosophie KISS
- Nous utiliserons
nanopour écrire les scripts (enfin... les flemmards) - Les courageux utiliserons un vrai éditeur:
vi
Les scripts
The first one
- Ouvrez votre éditeur favori (disons
viau hasard)$ vi script.sh - passez en mode "insertion" avec la touche 'i'
- Tapez exactement:
#!/bin/bash echo "Bonjour monde" - Tapez ensuite "esc" (passe en mode commande) suivi de ":wq" (sauvegarde et quitte)
- Ouvrez l'"autre" éditeur avec
$ nano script.sh - Tapez la même chose (pas de mode insertion ici)
#!/bin/bash echo "Bonjour monde" - Tapez ensuite "Ctrl-x" pour sauvegarder et sortir
Les scripts
- la manière la plus simple de lancer un script:
$ bash script.sh - La manière la plus standard:
$ chmod +x script.sh $ ls -l script.sh -rwxr-xr-x 1 rg rg 556 4 oct. 11:46 script.sh $ ./script.sh - En mode interactif
$ bash <script.sh - Dans l'environnement local
$ source script.sh
Les scripts
Modifiez votre script comme suit:
#!/bin/bash
nom="$1"
prenom="$2"
echo "Bonjour $prenom $nom"
Essayez le avec: (ce n'est pas interdit de changer le nom...)
$ ./script.sh Goll Renaud
$ ./script.sh Goll Renaud
Bonjour Renaud Goll
$
Qu'en concluez vous ?
Les scripts
Les structures de contrôle
La structure if liste; then liste; [elif liste; then liste; ] ... [else liste]; fi
- C'est la structure conditionnelle du bash
- La liste du if est exécutée. Si la valeur renvoyée est 0 (zéro), alors la liste du then est exécutée
- Si la valeur est différente de 0, la liste du elif est exécutée s'il y a lieu, sinon, celle du else s'il y a lieu
Les scripts
Les commandes [[ et test font appel à des primitives qui sont
-e fichier: vrai si fichier est un fichier-f fichier: vrai si fichier est un fichier standard-d fichier: vrai si fichier est un répertoire-z chaine: vrai si la longueur de chaine est nulle! primitive: inverse le résultat de primitive
#!/bin/bash
f="$1"
if [[ -z "$f" ]]; then
echo Argument non fourni >&2
exit 127
fi
if [[ -e "$f" ]]; then
echo "$f est un fichier et existe"
if [[ -f "$f" ]]; then
echo "$f est un fichier standard"
elif [[ -d "$f" ]]; then
echo "$f est un répertoire"
fi
else
echo "$f n'existe pas"
fi
Un script qui démontre qu'on peut faire n'importe quoi...
les scripts
La structure de contrôle
La structure while liste1; do liste2; done
- C'est une des structure de contrôle de boucle du bash
- La liste liste2 est répétée tant que le résultat de liste1 est nul
- il existe une commande
untilrarement utilisée qui a la même forme, sauf que liste2 est alors répétée tant que liste1 est non nul
exemple
while read ligne; do
##traitement de chaque ligne de "fichier"
done <fichier
Les scripts
La structure de contrôle
La structure for nom [ [in [ mot ... ] ]; ] do liste; done
- C'est une structure de boucle itérative
- La liste de mot suivant in est développé en une liste d'éléments.
- La variable nom prendra la valeur de chacun de ses éléments, et liste sera exécuté à chaque fois
exemple
for f in ./Documents/fichier{1..5}; do
echo "une ligne de plus" >>"$f"
done
Les scripts
La structure de contrôle
Une autre structure pour for: for (( expr1; expr2; expr3)); do liste; done
- C'est encore une structure itérative
- expr1 est une expression arithmétique qui est d'abord évaluée
- Ensuite, expr2 est évaluée répétitivement jusqu'à valoir 0
- Chaque fois que expr2 est évaluée, liste est exécutée et expr3 est évaluée
exemple
for (( i=0; i<10; i=i+1 )); do
echo "${i}eme passage"
done
## quelle est la différence avec:
for i in {0..9}; do
echo "${i}eme passage"
done
Package management
les paquets
- Une installation et une maintenance simple
- Des scripts de préinstallation et post-installation
- Gère les dépendances entre paquets
- RPM pour les distribution red-hat like
- dpkg pour les distributions debian like
- portage pour les distribution gentoo like
- sources dans tous les cas
- mais aussi snap, appimage...
redhat like
- basé sur rpm
- base de données dans /var/lib/rpm
- nom de fichier en .rpm ou .src.rpm
redhat like
- Installation:
rpm -i paquet.rpm - Suppression:
rpm -e paquet - Mise à jour d'un paquet, l'installe s'il ne l'est pas:
rpm -U paquet - Interrogation de la base installée:
rpm -q - Voir les informations sur un paquet (Query Insformation):
rpm -qi paquet - Lister les fichiers d'un paquet (Query List):
rpm -ql paquet - Lister les paquets installés (Query All):
rpm -qa - Vérifier un paquet:
rpm -V paquet
redhat like
yum: Yellow dog Updater Modified
- Permet de récupérer, installer, gérer les paquets depuis les dépôts
- Gère les dépendances
- Configuration dans /etc/yum.conf
- dépôts dans /etc/yum.repos.d
redhat like
yum: Yellow dog Updater Modified
- installation d'un paquet:
yum install paquet - recherche d'un paquet:
yum search paquet - suppression d'un paquet:
yum remove paquet - mise à jour d'un paquet:
yum update paquet - mise à jour des paquets:
yum update - dnf est a version moderne de yum.
Debian like
- basé sur dpkg
- base de données dans /var/lib/dpkg
- nom de fichier en .deb ou .src.deb
- pas de standardisation des noms
- pas d'URL
Debian like
- Installation:
dpkg -i paquet.deb - Suppression:
dpkg -r paquet - Suppression complète (y compris configuration):
dpkg -P paquet - Voir les informations sur un paquet:
dpkg -I paquet.deb - Trouver le paquet qui contient un fichier particulier:
dpkg -S /chemin/vers/fichier - Lister les paquets installés:
dpkg -l - Reconfiguration d'un paquet:
dpkg-reconfigure paquet - Et pour finir: pour cloner une machine, sur la première:
# dpkg --get-selections >mespaquets
Sur la deuxième
# dpkg --set-selections <mespaquets
# apt-get upgrade
Debian like
apt: Advanced Packaging Tool
- Permet de récupérer, installer, gérer les paquets depuis les dépôts
- Gère les dépendances
- Configuration dans /etc/apt
- dépôts dans /etc/apt/source.list et /etc/apt/source.list.d/
Debian like
apt: Advance Packaging Tool
- Mise à jour de la base:
apt update ## ou apt-get update sur les vieilles versions - installation d'un paquet:
apt install paquet - recherche d'un paquet:
apt search paquet ## ou apt-cache search paquet - suppression d'un paquet:
apt remove paquet - mise à jour de l'ensemble des paquets:
apt upgrade ## obsolete - mise à jour de l'ensemble des paquets avec saut de version majeure:
apt full-upgrade ## apt-get dist-upgrade - réparation des dépendances (quand c'est possible):
apt-get -f install - suppression des paquets inutiles (après une mises à jour majeure):
apt autoremove
Debian like
depuis les sources
- Téléchargez les sources
- décompactez (généralement:
$ tar -xvzf paquet.tar.gz) cd dossierDuPaquet./configuremakemake install
à vous
installez les paquets "sudo", "vim", "apt-transport-https", "lsb-release", "aptitude" et "build-essential" (sous-entendu: à partir des dépôts)
$ exit ## ???
...
login: root
password:
...
# apt update
...
# apt install sudo vim apt-transport-https lsb-release aptitude build-essential
...
...
# exit
...
login: monuser
password:
...
$
Don't take the name of root in vain
à vous
Mettez la machine à jour
$ exit
...
login: root
password:
...
# apt update
...
# apt full-upgrade
...
...
# apt autoremove
...
# exit
...
Configuration basique
Il faut bien commencer quelque part
Réseau
La configuration réseau se fait dans le fichier standard /etc/network/interfaces
Des fichiers additionnels peuvent être lus du dossier /etc/network/interfaces.d/* et inclus dans la configuration
Par défaut, la configuration réseau fait appel à un serveur DHCP
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
allow-hotplug ens18
iface ens18 inet dhcp
Le redémarrage du réseau peut se faire avec systemctl restart networking.service
Attention aux effet de bord ! (connexion ssh entre autre)
Réseau
On peut fixer une ip statique aussi
allow-hotplug ens18
iface ens18 inet static
address 192.168.5.210
netmask 24
gateway 192.168.5.1
dns-nameservers 192.168.5.1 192.168.5.2
Par ailleurs, la commande ip permet la configuration en live
ip addr add 192.168.5.210/24 dev ens18
ip route add default via 192.168.5.1
La résolution DNS se fait dans le fichier /etc/resolv.conf
domain exemple.com
search exemple.com
nameserver 192.168.5.1
nameserver 192.168.5.2
Gestion des utilisateurs
Tu vois, le monde se divise en deux catégories: ceux qui ont le pistolet chargé et ceux qui creusent.
Toi, tu creuses
Gestion des utilisateurs
- Un utilisateur est un identifiant numérique (UID)
- Il ne représente pas forcément un utilisateur physique
- Il est associé à au moins un identifiant de groupe (GID)
- L'ensemble des droits et limitations sont liés à ces identifiants: au niveau de filesystem, au niveau des autorisations d'accès ou des propriétés des processus
- La valeur de l'UID et du GID est comprise entre 0 et 65535 mais est sucseptible d'aller bien au delà (64 bits)
- Les valeurs inférieures à 100 sont "spéciales"
- Notament, l'UID/GID du root est 0/0
- L'UID d'un utilisateur physique commence souvent à 1000 (voir /etc/login.defs)
- De manière effective, le noyau gère 3 UIDs: le RUID (UID réel), le EUID (UID effectif) ainsi que le SUID (Saved UID)
- Les permissions des processus sont confrontés à l'EUID
Gestion des utilisateurs
Les groupes
- Chaque utilisateur fait au moins parti d'un groupe (chaque UID est lié à un GID au moins)
- Les autorisations de l'utilisateurs sont la somme des autorisations des groupes auquel il appartient
- Quand un utilisateur appartient à plusieurs groupes, il a un groupe primaire unique et des groupes secondaires. Le groupe primaire sera le groupe par défaut attribué à ses fichiers et processus
- Quand l'utilisateur est un utilisateur physique, par défaut, le nom de son groupe primaire est son nom d'utilisateur et il est le seul membre de ce groupe.
- Cela ne signifie pas que pour lui UID=GID
- Sous linux, un groupe ne peux pas faire parti d'un autre groupe
- La commande
idest une interface de visualisation de ses informations
Gestion des utilisateurs
Les commandes de gestion
useraddpermet d'ajouter un utilisateuradduseraussi ! mais de façon interactivegroupaddetaddgroupont les mêmes rôles mais pour les groupesusermodpermet de modifier les comptes existants- les fichiers (texte: rappelez vous la philosophie linux) de gestions des utilisateurs sont /etc/passwd, /etc/shadow, /etc/group et /etc/gshadow
- On peut modifier ces fichiers à la main, mais il est conseillé d'utiliser la commande
vipw - les commandes
userdeletgroupdelsupprime utilisateur et groupe en argument - les commandes
pwcketgrpckpermettent de vérifier la cohérence des fichiers de gestion des utilisateurs - Les commandes
passwdetchpasswdpermettent de changer le mot de passe - Les commandes
chage,chsh,chfnpermettent de gérer la validité des mots de passe, le shell ou les commentaires GECOS
Gestion des utilisateurs
TP
- La commande
whoamivous permet d'avoir votre nom de login, le fichier /dev/urandom génère des caractères aléatoires - Ajoutez les utilisateurs Titi, Toto, Tata, Tutu.
- Les utilisateurs devront avoir comme groupe principal users, un home peuplé avec /etc/skel, /bin/bash comme shell
- Il faudra leur communiquer un mot de passe (aléatoire !)
- Le mot de passe devra être immédiatement changé au premier login
$ for user in Titi Tata Toto Tutu; do \
sudo useradd -m -g users -s /bin/bash "$user"\
echo "$user:$(tr -cd 'a-zA-Z0-9' </dev/urandom | head -c 12)" >>pwd-file
done
$ sudo chpasswd <pwd-file
$ for user in Titi Tata Toto Tutu; do \
sudo chage -d 0 "$user"
done
$
Gestion des utilisateurs
TP
Changer votre login et votre répertoire de base par quelque chose qui vous correspond mieux (par exemple: prénom)
$ exit
...
login: autrelogin ## Il n'est pas possible de changer le login de l'utilisateur loggué
$ usermod --login renaud cpt01
$ mv /home/cpt01 /home/renaud
$ usermod --home /home/renaud renaud
$ exit
...
login: renaud
$
Filesystem
Filesystem
- C'est un système de classement permettant la gestion du disque dur (ou SSD), c'est à dire la mémoire de masse.
- Il en existe de multiple type: ext2, ext4, xfs, btrfs, zfs... Chacun de ces types réponds à une problématique donnée
- ils peuvent être associés (ou non) à un gestionnaire de partition tel que LVM2
- ext2 est souvent inclus dans le noyau, on l'utilisera lors du boot (dossier /boot)
- ext4 est le système standard, journalisé. C'est un FS en 32 bits (limité à des partition de 16To max)
- xfs est un système en 64 bits, plus rapide que ext4
- btrfs est le successeur de ext4. Il contient un gestionnaire de partition (et structure RAID) et est codé en 64 bits. Cela permet entre autre la gestion de snapshot
- zfs est un FS 128 bits avec gestionnaire de partition et structure RAID. Il gère les snapshots. Son inclusion dans le noyau linux est tardif (et dans sa version OpenZFS) pour cause d'incompatibilité de licence
Filesystem
Les outils
- Il existe plusieurs sortent de partition.
- On utilisera principalement une table de partition gpt ou dos sur les disques (attention, dos est un très vieux format)
- On pourra alors avoir 2 partitions principales et 1 partition étendue au maximum par disque
- Ceci est très insuffisant. On fera donc en sorte d'avoir des partitions logiques dans les partitions physique
- On utilise pour cela un gestionnaire de partition (LVM2) ou un FS capable de gérer le partitionnement (btrfs ou zfs)
- Les partitions logiques et physiques se chevauchent donc
- L'utilitaire
fdiskpermet la gestion des partitions physiques - Il est souvent remplacé par l'utilitaire
partedqui peut gérer les partitions gpt
Filesystem
Les outils
$ sudo fdisk -l
# affiche les toutes les partitions du système
$ sudo fdisk /dev/vda # édite les partitions du disque /dev/vda
# ATTENTION: vous êtes sur le disque système réel
# QUITTEZ en faisant 'q'
Filesystem
Les outils
- pour les système extN et xfs, on utilisera de préférence un gestionnaire de partition
- LVM2 est le gestionnaire de partition standard sous linux.
- Il fait la distinction entre volume "physique" (il s'agit en réalité de partitions), groupe de volume et partition
- Les commandes permettant de gérer LVM sont nombreuses
- Essayez
lvs,vgsetpgs(avec les droits root)
Filesystem
Les outils
- Pour la gestion des partitions logiques
- La gestion des volumes physiques (qui sont donc des partitions physiques) se fait avec
pvs, pvcreate, pvmove, pvremove, pvdisplay - Une fois les volmumes physiques marqués, il faut les associer à un groupe de volume
- Cette gestion se fait avec les commandes
vgs, vgcreate, vgchange, vgremove, vgdisplay... - Une fois le(s) groupe(s) de volume créé(s), on peut y installer des partitions
- La gestion des partitions se fait avec
lvs, lvcreate, lvchange, lvremove, lvdisplay... - Ce n'est qu'ensuite qu'on pourra formater (c'est à dire installer un système de fichier), puis monter le volume (càd attacher l'arborescence du volume à l'arborescence du système)
Filesystem
Les outils
- Le formatage
- La commande permettant de formater une partition est
mkfs. Il s'agit d'un front-end vers d'autres commandes
$ sudo mkfs [-t type] [fs-option] device
-t: permet de spécifier le FS a initialiser. Ex: ext2, ext4 ou xfsfs-option: permet de passer les options spécifiques au système de fichierdevice: le device (la partition) considérée
Filesystem
- Chaque FS peut avoir des options spécifiques
- En cas d'utilisation de ext4, la commande appelée par
mkfsestmkfs.ext4qui appelle lui mêmemke2fs - En cas d'utilisation de xfs, la commande appelée est
mkfs.xfs - Dans le cas de mkfs, il est tout à fait possible de fournir comme device un fichier standard:
initialisera un FS ext4 dans le fichier MonFichier. Celui ci pourra ensuite être monté$ mkfs -t ext4 MonFichier
Filesystem
Les outils
- le montage
- C'est l'opération qui consiste à attacher au système de fichier un système de fichier étranger (exemple, attacher une clé USB)
- On utilise pour cela la commande
mountmount [-t fstype] [-o options] device dir -t: généralement non fourni car reconnu: ext4, xfs...-o: options du FS: par exemple ro pour ext4 (montage Read-Only, très util en cas de récupération de backupdevice: c'est le device qu'on monte. Pour une clef USB, ça pourrait être /dev/sdb. Peut être un fichier standarddir: répertoire dans lequel on va attacher l'arborescence du device. Attention, si ce répertoire n'est pas vide, son contenu va être masqué- Il faut ensuite démonter le device (commande
umount)
Filesystem
À vous
- Créez un fichier de 100Mo plein de '0' (/dev/zero et commande dd et ses options if, of, bs et count)
- Formatez ce fichier en ext4
- Montez le et créez un répertoire ou un fichier dedans
$ dd if=/dev/zero of=./fichier.raw bs=100M count=1
...
$ sudo mkfs -t ext4 fichier.raw
...
$ mkdir tmp
$ sudo mount ./fichier.raw ./tmp
$ sudo chown $(whoami): ./tmp
$ mkdir ./tmp/mondossier
$ echo coucou >./tmp/mondossier/monfichier
Filesystem
Les outils
- Un certain nombre de commande permettent de gérer les FS
dfpermet de voir l'espace disponibledupermet de voir l'espace occupé par un répertoirefsckpermet de réparer un FS (équivalent de chkdsk pour windows)dumpe2fspermet l'affichage des paramettres d'un FStune2fsest un utilitaire permettant le réglage de nombreux paramètres d'un FS ext2, 3 ou 4- les commandes
lsblketblkidvous permettent de récupérer les UUID des partitions - Vous noterez l'absence de commande de défragmentation... les FS sont faits pour ne jamais en avoir besoin
Filesystem
le fichier /etc/fstab
- C'est le fichier qui fixe les montages au démarrage du système. Il est lu au cours du boot
- son format est
device DossierMontage TypeFS Options FrequenceDump FrequenceFsck - exemple
/dev/vda1 / ext4 errors=remount-ro 0 1 /dev/vda2 /home xfs defaults 0 2
Démarrage
(désolé, j'ai pas d'image)
En tapant "démarrage" sur google, je n'ai trouvé que des images de windows 10/11 avec
"comment démarrer son pc plus vite"
Honnêtement, moi je sais...
Installez Linux :-)
Démarrage
- Il existe 2 manières standards de démarrer
- System V est le système d'origine, il lance un process (pid 1) appelé init
- Il est séquentiel: chaque service se lance dans l'ordre déterminé par le système pour atteindre un niveau
- Il y a 6(,5) niveaux
- 0: Halt. Arrêt de l'OS (pas forcément arrêt électrique de la machine)
- 1: Mono-utilisateur avec service minimum, utilisé pour de la maintenance
- 2: Mono-utilisateur sans réseau, console
- 3: Multi-utilisateurs, avec réseau, console (mode standard, hors graphique)
- 4: Comme le 3, configurable par le sysadmin
- 5: Multi-utilisateurs, avec réseau, avec serveur X (serveur graphique)
- 6: reboot
- S,s: Mode de récupération
Démarrage
Systemd
- systemd n'utilise pas de niveau, mais des target
- L'ensemble des services se lance grace à un jeu de dépendance
- Un service dépend éventuellement d'un autre service et fourni un état
- La résolution de l'arborescence permet de démarrer les services en parallèle
- Par exemple, sshd (service ssh) fourni par multi-user.target dépend de network.target
- La configuration des services est géré dans /etc/systemd
Démarrage et gestion
La commande unique permettant de gérer les services et les target est systemctl
systemctl get-defaultpermet d'obtenir la target par défautsystemctl set-default New.Targetpermet de fixer la target par défautsystemctl list-dependencies multi-user.targetpermet de lister sous forme arborescente les dépendances d'une target
Démarrage et gestion
La commande systemctl permet aussi de gérer les services et de les inscrire dans une target
systemctl status srv.servicepermet de connaître le statut du service srvsystemctl enable srv.servicepermet d'inscrire pour un démarrage automatique dans la cible courante le service srvsystemctl start srv.servicepermet de démarrer un servicesystemctl stop srv.servicepermet de stoper un servicesystemctlpermet de lister tous les services et leur état
gestion des process
- Les process sont des "programmes" en cours d'exécution. On y retrouve les services mais aussi les applications
- La liste des process et de leur pid s'affiche avec la commande
ps. PAr défaut, seuls les process de l'utilisateur sont affichés$ ps PID TTY TIME CMD 2996 pts/0 00:00:00 bash 3133 pts/0 00:00:00 ps - La commande
toppermet d'avoir une vision dynamique des process; entre autre avec leur consommation de ressources - On peut envoyer des messages (les signaux) à travers le service de messagerie du noyau avec la commande mal nommée
kill. Les plus courants sont- SIGTERM : oblige l'applciation à terminer
- SIGKILL : kill le process (directement au niveau du noyau)
- SIGHUP : habituellement, oblige un service à relire ses fichiers de configuration
- SIGUSR1 et SIGUSR2: user defined
- SIGSTOP: stop un process (ne le tue pas: lui interdit simplement de s'exécuter)
- SIGSTART: redémarre le process s'il a été préallablement stopé
Noyau
Image par CharlesC sur wikipedia.fr, CC-BY-SA 3.0
Noyau
- Le noyau linux est un noyau monolithique modulaire
- Cela signifie qu'il est relativement gros et intègre dans son corps la plupart des pilotes
- On peut néanmoins en rajouter sous forme de module
- Le noyau fonctionne dans un mode particulier: le mode noyau (!). Le deuxième mode est le mode utilisateur
- Le but d'un noyau est de passer le moins de temps possible en mode noyau. Ainsi, un pilote fonictionnera le plus possible en mode utilisateur et ne passera en mode noyau qu'au moment de l'accès matériel.
- Le mode noyau est réservé au noyau: aucune application utilisateur n'y tourne jamais
- La transition entre mode noyau et mode utilisateur est couteuse en cycles, c'est la principale raison de la perte de performance dans les systèmes virtualisés.
noyau
- Les information sur le noyau sont accessibles via la commande
unameet ses options uname -s: Le nom du noyauuname -i: la plateformeuname -r: la révision du noyauuname -a: toutes les informations disponibles
$ uname -a
Linux INFAL51 5.10.0-20-amd64 #1 SMP Debian 5.10.158-2 (2022-12-13) x86_64 GNU/Linux
$
Modules
- Les modules disponibles sont présents dans /lib/modules/[version-noyau]
- Ils possèdent l'extension .ko; ce sont fondamentalement des fichiers objets (.o) pour le kernel (le k)
- On peut les lister avec la commande
lsmod - La commande
modinfofournit des informations sur les modules - L'ajout (le chargement) et retrait d'un module se font avec la commande
modprobe - L'ensemble de la configuration des modules se fait dans /etc/modprobe.d
/proc
- /proc est un dossier virtuel, il est instancié par le noyau et n'a pas d'existance physique sur le disque
- N'écrivez pas dedans sans savoir ce que vous faites ! À titre d'exemple, le fichier /proc/sys/net/ipv4/ip_forward définit le routage en ipv4
- un certain nombre de fichier peuvent être utils à l'analyse d'un système:
- /proc/cpuinfo: contient des information sur les processeurs
- /proc/meminfo: contient des informations sur la mémoire
- /proc/devices: contient des informations sur les devices
- /proc/modules: contient des informations sur les modules chargés (même résultat que lsmod, en moins propre !)
- /proc/mount: informations sur les montages (même résultat que mount sans options)
Journaux
Image par Altego, wikipedia.fr, CC-BY-SA
Journaux système
- Le noyau, au démarrage, journalise ses informations dans le kernel ring buffer
- C'est un espace limité en taille et réservé au noyau
- On y accède à travers la commande
dmesg-l, --level: permet de restreindre l'affichage au niveau demandé:$ sudo dmesg --level=err,warn #permet de restreindre au niveau error et warning-H: lisible par un humain...
Journaux système
- Une fois le système démarré, la journalisation fonctionne grace au service syslog (ou un de ses dérivés: rsyslog sur debian). à partir de la version 12 de debian, rsyslog est abandonné au profit de journald.
- Ces services classent l'information fonction d'un sous système applicatif (appelé facility) et en niveaux
- Sa configuratyion se fait dans
/etc/rsyslog.conf, notamment le fait de déporter les logs - Parmi les facilities remarquables, on peut citer:
- kern: fichier /var/log/kern.log: message du noyau
- auth: fichier /var/log/auth.log: messages relatifs à l'authentification
- syslog: fichier /var/log/syslog: messages de rsyslog lui même (principale source de recherche d'erreur)
- local0 à local7: configuration par le sysadmin
- La commande
journalctlpermet de visualiser les logs d'un service particulier
Journaux système
- Les niveaux permettent de classer la criticité de l'information
- debug: information de débogage
- info: informations quelconques
- notice: informations pertinentes
- warn: avertissement
- err: erreur
- crit: conditions critiques
- alert: conditions critiques et urgence
- emerg: urgence maximale sur erreur critique (il est probable que le système de ne soit plus utilisable à ce niveau là)
Journald
Journald est un mini ELK. Il permet notamment l'indexation des logs et donc une consultation plus rapide. Il est structurellement plus lourd que rsyslog.
Sa configuration se fait dans /etc/systemd/journald.conf
Une fois configuré, le service doit être redémarrer avec systemctl reload systemd-journald.service. Dans les première version, il fallait un redémarrage complet du service (restart à la place de reload).
Journald
journalctl est la commande qui permet de manipuler les logs. Il utilise less comme pager.
journalctl -n 20affiche les 20 dernières lignes, de la plus vieille à la plus récente.journalctl -f(follow) affiche les lignes en continue (c'est l'équivalent detail -f)journalctl --no-pagerpermet d'utiliser journalctl avec des filtres (comme grep, par exemple).
Journald
Le rand avantage de journald par rapport à syslog est sa possibilité de filtrer les logs par service
journalctl -u servicepermet de lister les logs d'un service particulier.journalctl --list-bootspermet de lister les démarrages de la machine
Comme pour rsyslog, les logs peuvent être centralisés.
Les trucs en vrac
- allez voir dans
/etc/network/interfaces: c'est la config réseau du système ipest la commande de gestion des interfaces réseau- essayez
ip addr showouip link show - À votre avis, que fait
ip addr set 192.168.0.24/24 dev enp58s0f1? - La commande
netcatest le couteau suisse de l'administrateur réseau - Mais on peut aussi utiliser aussi
netrwetnetsed